在當(dāng)今數(shù)據(jù)驅(qū)動(dòng)的時(shí)代,大數(shù)據(jù)技術(shù)已成為眾多行業(yè)轉(zhuǎn)型升級(jí)的關(guān)鍵引擎。學(xué)習(xí)大數(shù)據(jù)技術(shù),遠(yuǎn)不止于理解其概念與架構(gòu),更重要的是熟練掌握一系列核心工具,以實(shí)現(xiàn)高效、可靠的數(shù)據(jù)處理。這不僅是技術(shù)能力的體現(xiàn),更是將數(shù)據(jù)價(jià)值轉(zhuǎn)化為業(yè)務(wù)洞察力的實(shí)踐基礎(chǔ)。
一、 理解大數(shù)據(jù)技術(shù)的基石:從概念到生態(tài)
學(xué)習(xí)大數(shù)據(jù)技術(shù),首先需明晰其核心特征——通常以“4V”(Volume體量、Velocity速度、Variety多樣、Value價(jià)值)概括。這決定了傳統(tǒng)數(shù)據(jù)處理方式難以為繼,催生了以Hadoop、Spark等為代表的分布式計(jì)算框架。這些框架構(gòu)成了大數(shù)據(jù)處理的底層基礎(chǔ)設(shè)施,其設(shè)計(jì)哲學(xué)(如分而治之、移動(dòng)計(jì)算而非移動(dòng)數(shù)據(jù))是理解所有上層工具的邏輯起點(diǎn)。
二、 掌握數(shù)據(jù)處理的核心工具鏈
數(shù)據(jù)處理是大數(shù)據(jù)技術(shù)棧中承上啟下的核心環(huán)節(jié),涉及采集、存儲(chǔ)、計(jì)算、分析等多個(gè)階段,每個(gè)階段都依賴特定的工具集。
- 數(shù)據(jù)采集與傳輸工具:數(shù)據(jù)處理的源頭。需要掌握如Apache Kafka(高吞吐量分布式消息隊(duì)列)、Flume(日志收集)、Sqoop(關(guān)系數(shù)據(jù)庫(kù)與Hadoop間數(shù)據(jù)傳輸)等,它們負(fù)責(zé)從各類源頭實(shí)時(shí)或批量地將數(shù)據(jù)匯聚到數(shù)據(jù)湖或數(shù)據(jù)倉(cāng)庫(kù)中。
- 數(shù)據(jù)存儲(chǔ)與管理工具:數(shù)據(jù)的安居之所。HDFS(Hadoop分布式文件系統(tǒng))是經(jīng)典的批量數(shù)據(jù)存儲(chǔ)基石;而面對(duì)實(shí)時(shí)查詢,則需要掌握HBase(列式數(shù)據(jù)庫(kù))、Cassandra等NoSQL數(shù)據(jù)庫(kù)。數(shù)據(jù)倉(cāng)庫(kù)工具如Hive(提供SQL接口查詢HDFS數(shù)據(jù))和云原生數(shù)據(jù)湖倉(cāng)一體方案(如Delta Lake、Iceberg)也日益重要。
- 數(shù)據(jù)計(jì)算與處理引擎:這是發(fā)揮數(shù)據(jù)價(jià)值的核心“發(fā)動(dòng)機(jī)”。
- 批處理:Apache Spark憑借其內(nèi)存計(jì)算和豐富的API(Scala、Java、Python、R),已成為批處理的首選,其性能遠(yuǎn)超經(jīng)典的MapReduce。
- 流處理:對(duì)于實(shí)時(shí)數(shù)據(jù)流,需掌握Apache Flink(低延遲、高吞吐、狀態(tài)精確一次處理)或Spark Streaming(微批處理模型)。
- 交互式查詢:工具如Presto、Impala,能夠?qū)A繑?shù)據(jù)進(jìn)行亞秒級(jí)交互式SQL查詢。
- 數(shù)據(jù)調(diào)度與協(xié)調(diào)工具:確保復(fù)雜的數(shù)據(jù)處理流程有序、自動(dòng)化運(yùn)行。Apache Airflow(以代碼定義工作流)和DolphinScheduler是任務(wù)調(diào)度的主流選擇;而ZooKeeper則提供分布式協(xié)調(diào)服務(wù),保障集群的可靠運(yùn)行。
三、 構(gòu)建高效數(shù)據(jù)處理能力的關(guān)鍵實(shí)踐
僅僅知道工具名稱遠(yuǎn)遠(yuǎn)不夠,真正的掌握體現(xiàn)在:
- 環(huán)境搭建與集群管理:能夠在本地或云上(如AWS EMR、阿里云EMR)熟練部署、配置和維護(hù)一個(gè)大數(shù)據(jù)集群,理解各組件間的協(xié)作關(guān)系。
- 編程與開(kāi)發(fā):深入使用至少一種主流語(yǔ)言(推薦Scala或Python)進(jìn)行Spark/Flink應(yīng)用開(kāi)發(fā),編寫(xiě)高效、健壯的數(shù)據(jù)處理作業(yè)。
- 性能調(diào)優(yōu):能夠根據(jù)數(shù)據(jù)特性和業(yè)務(wù)需求,對(duì)作業(yè)進(jìn)行性能調(diào)優(yōu),例如調(diào)整Spark的并行度、內(nèi)存分配、選擇合理的存儲(chǔ)格式(如Parquet、ORC)與壓縮算法。
- 問(wèn)題排查與調(diào)試:熟練查看各類工具的運(yùn)行日志(如YARN日志、Spark UI),快速定位并解決數(shù)據(jù)處理過(guò)程中的故障與瓶頸。
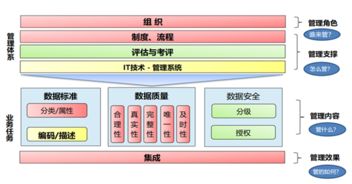
- 融入數(shù)據(jù)治理與質(zhì)量:在數(shù)據(jù)處理流程中融入數(shù)據(jù)質(zhì)量檢查、元數(shù)據(jù)管理(如Apache Atlas)和數(shù)據(jù)血緣追蹤的意識(shí),確保產(chǎn)出數(shù)據(jù)的可信度。
四、 學(xué)習(xí)建議與路徑規(guī)劃
建議采取“理論->核心工具->系統(tǒng)實(shí)踐”的路徑:
- 夯實(shí)理論基礎(chǔ):理解分布式系統(tǒng)原理、CAP定理、數(shù)據(jù)模型等。
- 聚焦核心工具:優(yōu)先深度掌握Hadoop(HDFS, YARN)、Spark(Core, SQL, Streaming)和一門(mén)數(shù)據(jù)庫(kù)(如Hive或HBase)。
- 動(dòng)手實(shí)踐項(xiàng)目:從搭建環(huán)境開(kāi)始,完成一個(gè)端到端的數(shù)據(jù)處理項(xiàng)目,例如“網(wǎng)站日志分析系統(tǒng)”,涵蓋數(shù)據(jù)采集(Kafka)、存儲(chǔ)(HDFS/Hive)、處理(Spark)、可視化等全流程。
- 拓展與深化:根據(jù)興趣方向,深入流處理(Flink)、云原生大數(shù)據(jù)架構(gòu)或特定領(lǐng)域(如機(jī)器學(xué)習(xí)庫(kù)MLlib)。
學(xué)習(xí)大數(shù)據(jù)技術(shù)是一場(chǎng)結(jié)合深度與廣度的旅程。對(duì)數(shù)據(jù)處理工具的熟練掌握,是將大數(shù)據(jù)宏偉藍(lán)圖變?yōu)楝F(xiàn)實(shí)生產(chǎn)力的關(guān)鍵階梯。唯有通過(guò)持續(xù)的理論學(xué)習(xí)、工具實(shí)踐和項(xiàng)目錘煉,才能在大數(shù)據(jù)的浪潮中游刃有余,真正駕馭數(shù)據(jù),賦能決策與創(chuàng)新。